4.6.6.1. Algoritmo de la ruta más corta (Algoritmo de Dijskstra)
4.7. Grafos planos
4.7.1. Grafos homeomorfos 4.7.2. Teorema de Euler 4.7.3. Teorema de Kuratowski
4.8. Coloración de grafos
4.8.1. Teorema de los cuatro colores
ÁRBOLES
5.1. Propiedades de los árboles 5.2. Árboles generadores
5.2.1. Búsqueda en anchura (BFS) 5.2.2. Búsqueda en profundidad (DFS)
5.3. Árboles generadores minimales
5.3.1. Algoritmo de Prim 5.3.2. Algoritmo de Kruskal
5.4. Recorrido de árbol 5.4.1. Notación prefija y posfija
4.5 Grafos de similaridad
Los grafos de similaridad permiten agrupar información con características
semejantes. Esto implica formar subgrafos en donde los vértices de un
subgrafo están relacionados entre sí, pero no tienen relación con los vértices
del otro subgrafo, ya que no son similares. Una aplicación de este tipo de
grafos se encuentra en el reconocimiento de patrones, en donde se agrupa
información con propiedades muy parecidas de tal manera que se puedan
detectar enfermedades como el cáncer, al agrupar conjuntos de células que
comparten características similares. Otra aplicación se encuentra en la
cartografía, en donde grupos de píxeles (pequeños cuadritos de una imagen) se
agrupan porque son muy parecidos y por lo tanto se confieran similares.
En este tipo de grafo se debe definir una función que permita determinar la
similaridad que existe entre los vértices, principalmente la distancia entre sus
características.
Por ejemplo, la siguiente tabla muestra las características que tienen las
diferentes partes de tejido de igual sección transversal de un análisis de
mama, de acuerdo con “temperatura”, “intensidad de color” e “inflamación”.
Donde, la finalidad es determinar los grafos de similaridad para un coeficiente
de inferencia C = 5.
Lo primero que se debe de hacer es obtener la distancia entre los puntos Px y
Py por medio de la siguiente función:
Se observa claramente que entre P1 y P1 existe una gran similaridad, es más,
son iguales. Por lo tanto, no tiene caso obtener la similaridad entre puntos
iguales, de forma que se da por hecho que son similares y solamente se
registrarán al final en el grafo correspondiente.
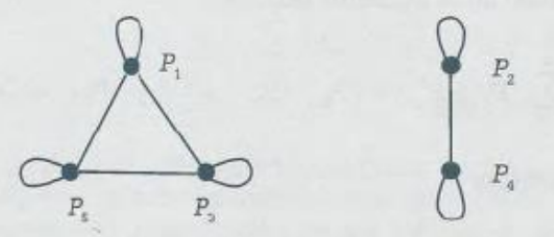
Se considera que dos puntos son similares si ( ) y en este caso se tiene que ( )
, con lo cual se puede decir que el grafo está dividido en dos partes como se
muestra a continuación:
Los lazos en cada uno de los vértices significan la similaridad entre ellos
mismos. Con los grafos anteriores se puede considerar que las partes de tejido
P1, P3, P5 son similares, así como P2 y P4 también lo son. Si se considera un
mayor daño en las células cuyas características de temperatura, color e
inflamación están más alejadas de los valores normales, se puede concluir que
las áreas más dañadas son P1, P3 y P5.
4.6. Grafos conexos
Un
camino en un multigrafo G consta de una secuencia alternada de vértices
y aristas de la forma v0, e1, v1, e2, v2, ..., en−1, vn−1, en, vn donde
cada arista ei contiene a los vértices vi−1 y vi (que aparecen a los
lados de ei en la secuencia). El número n de aristas se denomina
longitud del camino. Cuando no hay ambigüedad, un camino se denota por
su secuencia de vértices (v0, v1, . . . , vn). Se dice que el camino es
cerrado si v0 = vn. En caso contrario, se dice que el camino es de v0 a
vn o entre v0 y vn , o que une v0 y vn.
Un
camino simple es un camino en el que todos los vértices son distintos.
(Un camino en que todas las aristas son diferentes se denomina
recorrido.) Un ciclo es un camino cerrado de longitud 3 o más donde
todos los vértices son distintos excepto v0 = vn. Un ciclo de longitud k
se denomina k-ciclo.
EJEMPLO: Considere el grafo G en la figura Considere las siguientes secuencias:
La secuencia α es un camino de P4 a P6; pero no es un recorrido porque la arista {P1, P2} se usa dos veces. La secuencia β no es un camino porque no hay arista {P2, P6}. La secuencia γ es un recorrido porque ninguna arista se usa dos veces; pero no es un camino simple porque el vértice P5 se usa dos veces. La secuencia δ es un camino simple de P4 a P6; pero no es el camino más corto (respecto a la longitud) de P4 a P6. El camino más corto de P4 a P6es el camino simple (P4, P5, P6), cuya longitud es 2.
Al eliminar aristas innecesarias, no es difícil ver que cualquier camino desde un vértice u hasta un vértice v puede sustituirse por un camino simple de u a v. Este resultado se plantea formalmente a continuación.
Teorema. Hay un camino de un vértice u a un vértice v si y sólo si existe un camino simple de u a v. (José Francisco Villalpando Becerra, Andrés García Sandoval, 2014).
4.6.1 Conectividad, componentes conexos
Un grafo G es conexo si existe un camino entre dos de sus vértices. El grafo en la figura a) es conexo, pero el grafo en la figura b) no es conexo ya que, por ejemplo, entre los vértices D y E no hay ningún camino.
Suponga que G es un grafo. Un subgrafo conexo H de G se denomina componente conexo de G si H no está contenido en ningún subgrafo conexo más grande de G. Resulta intuitivamente claro que cualquier grafo G puede partirse en sus componentes conexos. Por ejemplo, el grafo G en la figura 8-8b) tiene tres componentes conexos, los subgrafos inducidos por los conjuntos de vértices {A, C, D}, {E, F} y {B}.
El vértice B en la figura b) se denomina vértice aislado porque B no pertenece a ninguna arista o, en otras palabras, grd(B) = 0. En consecuencia, como se observó, B mismo forma un componente conexo del grafo.
Observación: En términos formales, en el supuesto de que cualquier vértice u esté unido consigo mismo, la relación “u está unido con v” es una relación de equivalencia sobre el conjunto de vértices de un grafo G y las clases de equivalencia de la relación constituyen los componentes conexos de G.
4.6.2.1 Distancia y diámetro
Considere un grafo conexo G. La distancia entre los vértices u y v en G, que se escribe d(u, v), es la longitud de la ruta más corta entre u y v. El diámetro de G, lo cual se escribe diám(G), es la distancia máxima entre dos puntos cualesquiera en G. Por ejemplo, en la figura 8-9a), d(A, F) = 2 y diám(G) = 3, mientras que en la figura 8-9b), d(A, F) = 3 y diám(G) = 4.
4.6.2.2 Camino simple
Un camino es una sucesión de lados en la cual todos los lados son distintos. Así, un camino simple es una sucesión de lados en la cual todos los lados y todos los vértices son distintos
4.6.2.3 Camino cerrado
Un circuito es un camino que inicia y termina en el mismo vértice donde todos sus lados son distintos y un circuito simple es un circuito en el cual todos los lados y todos los vértices son distintos, a excepción del primero y último vértices, que en realidad son el mismo.
Ejemplo
Sea G=(V, E) el grafo no dirigido. Determinar si las sucesiones de lados de la tabla corresponden a un
camino, camino simple, circuito o circuito simple.
Sucesiones de lados del grafo de la figura.
Solución de las sucesiones de lados de la tabla
4.6.4 Grafos Eulerianos
Sea G un grafo. Un circuito de Euler para G es un circuito que contiene cada vértice y cada arista de G. Es decir, un circuito de Euler para G es una sucesión de vértices adyacentes y aristas en G que tiene al menos una arista, que comienza y termina en el mismo vértice, utiliza cada vértice de G por lo menos una vez y cada arista de G exactamente una vez.
4.6.4.1 Paseo de Euler
Un paseo de Euler (o euleriano) es un camino que incluye todos los lados de un grafo dado una y solo una vez.
4.6.4.2 Circuito de Euler
Un circuito de Euler (o euleriano) es un circuito que incluye todos los lados de un grafo dado una y solo una vez. Al recorrer todos los lados del grafo, también se recorren todos los vértices del grafo; sin embargo, no importa la repetición de vértices, mientras no se repitan los lados
Ejemplo;
Sean los grafos dirigidos de la siguiente figura. Verificar si dichos grafos tienen un paseo o un circuito de Euler.
Si consideramos las condiciones antes descritas, el grafo G1 tiene tanto un paseo como un circuito de Euler, ya que cualquiera de sus vértices, de manera individual, tiene la misma valencia de entrada que de salida. En cambio, el grafo G2 únicamente tendrá un paseo de Euler, pero no un circuito de Euler, ya que la valencia de entrada de cualquier vértice, de manera individual, es igual a su valencia de salida, con la posible excepción de solo dos vértices.
4.6.5 Grafos Hamiltonianos
Un circuito hamiltoniano en un grafo G, así denominado en honor del matemático irlandés del siglo
XIX William Hamilton (1803-1865) es un camino cerrado que visita todos los vértices en G exactamente una vez. (Este camino cerrado debe ser un ciclo.) Si G admite un circuito hamiltoniano, entonces G se denomina grafo hamiltoniano. Observe que un circuito de Euler recorre cada arista exactamente una vez, aunque puede repetir vértices, mientras que un circuito hamiltoniano visita cada vértice exactamente una vez aunque puede repetir aristas. En la figura 8-11 se proporciona un ejemplo de uno que es hamiltoniano pero no euleriano y viceversa.
Aunque resulta evidente que sólo los grafos conexos pueden ser hamiltonianos, no hay ningún criterio simple para decidir si un grafo es o no hamiltoniano, como sí lo hay para el caso de los grafos eulerianos. Se cuenta con la siguiente condición suficiente, que se debe a G. A. Dirac.
Teorema: Sea G un grafo conexo con n vértices. Entonces G es hamiltoniano si n ≥ 3 y n ≤ grd(v) para cada vértice v en G.(José Francisco Villalpando Becerra, Andrés García Sandoval, 2014).
4.6.5.1 Paseo Hamiltoniano
Un paseo de Hamilton (o hamiltoniano) constituye un camino que pasa a través de cada uno de los vértices de un grafo dado exactamente una vez.
4.6.5.2 Circuito de Hamilton
Un circuito de Hamilton (o hamiltoniano) es un circuito que pasa a través de cada uno de los vértices de
un grafo dado exactamente una vez. Al recorrer todos los vértices del grafo, no es importante si no se recorren todos los lados del grafo.
EJEMPLO
Sea el grafo no dirigido G=(V, E)
En dicho grafo, la sucesión de lados: (v1, v2, v3, v4, v5, v6, v7) es un paseo de Hamilton. En tanto que la sucesión de lados:(v1, v7, v2, v3, v4, v5, v6, v1) es un circuito de Hamilton.
4.6.6 Grafos ponderados
Un grafo G se denomina grafo etiquetado si sus aristas y/o vértices son datos asignados de un tipo o del otro. En particular, G se denomina grafo ponderado si a cada arista e de G se asigna un número no negativo w(e) denominado peso o longitud de v. En la figura se muestra un grafo ponderado, en el que el peso de cada arista se proporciona en forma evidente. El peso (o la longitud) de un camino en tal grafo ponderado G se define como la suma de los pesos de las aristas en el camino. Un problema importante en teoría de grafos es encontrar el camino más corto; es decir, un camino de peso (longitud) mínimo(a), entre dos vértices arbitrarios dados. La longitud de un camino más corto entre P y Q en la figura es 14; un camino es (P, A1, A2, A5, A3, A6, Q).
Ejemplo
En la siguiente figura se muestra un grafo ponderado, el cual es simplemente un grafo con datos o valores que le han sido asignados a sus lados
4.7 Grafos planos
Un grafo G se denomina plano si se puede dibujar en el plano con sus aristas intersecándose sólo en los vértices de G.
4.7.1 Grafos homeomorfos
Dado cualquier grafo G, es posible obtener un nuevo grafo al dividir una arista de G con vértices adicionales. Dos grafos G y G∗ son homeomorfos, si es posible obtenerlos a partir del mismo grafo o grafos isomorfos al aplicar este método. Los grafos a) y b) en la figura no son isomorfos, aunque son homoeomorfos puesto que pueden obtenerse a partir del grafo c) al agregar vértices apropiados.
Ejemplo
Sean los grafos no dirigidos G1 (V1, E1) y G2 (V2, E2).
Determinar si estos grafos son homeomorfos.
Como G1 y G2 son grafos isomorfos mediante repeticiones de inserciones y eliminaciones de vértices de valencia 2, como se muestra en la figura; entonces, se considera que son homeomorfos.
4.7.2 Teorema de Euler
Teorema: Un grafo conexo finito es euleriano si y sólo si cualquier vértice tiene grado par.
4.7.3 Teorema de Kuratowski
Un grafo es aplanable si, y solo si, no contiene ningún subgrafo que sea homeomorfo a alguno de los llamados grafos de Kuratowski. Los grafos de Kuratowski se observan con detalle en la figura. Dichos grafos son K5 y K3,3, respectivamente.
Teorema: Un grafo es no plano si y sólo si contiene una subgrafo homeomorfo a K3, o a K5.
Ejemplo
Sea el grafo G = (V, E) completo K6 que se muestra en la figura. Determinar si este grafo es aplanable.
En este caso, primero se rota a K6, como se muestra en la figura i). Si se eliminan los lados horizontales internos, se obtiene el subgrafo que se observa en la figura ii). Después, si se eliminan los lados inclinados externos, tanto superiores como inferiores, se obtiene el subgrafo de la figura iii), el cual es K3,3. Por último, alargando o reduciendo la distancia de los lados verticales, se obtiene el subgrafo de la figura iv), el cual efectivamente ratifica que es K3,3. Por tanto, se dice que K6 tiene un subgrafo homeomorfo a K3,3 dicho grafo no es aplanable.
4.8. Coloración de grafos
El coloreado de un grafo no dirigido conexo G (V, E) ocurre cuando se asignan colores a los vértices
de G, de modo que si vi y vj son adyacentes, entonces vi y vj tendrán colores distintos asignados. El número mínimo de colores necesarios para el coloreado propio de un grafo es lo que se conoce como número cromático del grafo. Considere un grafo G. Un coloreado de vértices, o simplemente coloreado de G, es una asignación de colores a los vértices de G de modo que vértices adyacentes tengan diferentes colores. Se dice que G es n-coloreable si existe un coloreado de G en el que se usan n colores. (Puesto que el término “color” se usa como sustantivo, se intentará evitar su uso como verbo al decir, por ejemplo, “pintura” G en lugar de “color” G cuando se asignen colores a los vértices de G.) El número mínimo de colores necesarios para pintar a G se denomina número cromático de G y se denota por χ(G). En la figura se proporciona un algoritmo propuesto por Welch y Powell para el coloreado de un grafo G. Se recalca que este algoritmo no siempre produce un coloreado mínimo de G.
Algoritmo de Welch y Powell: La entrada es un grafo G.
Paso 1. Los vértices de G se ordenan en orden decreciente de grado.
Paso 2. El primer color C1 se asigna al primer vértice y después, en orden secuencial, C1 se asigna a cada vértice
que no sea adyacente al vértice previo al que se asignó C1.
Paso 3. El paso 2 se repite con un segundo color C2 y la subsecuencia de vértices no coloreados.
Paso 4. El paso 3 se repite con un tercer color C3, y luego con un cuarto color C4, hasta que todos los vértices
estén coloreados.
Paso 5. Salir.
EJEMPLO
a) Considere el grafo G en la figura. Se aplica el algoritmo de Welch y Powell, para obtener un coloreado de G. Cuando los vértices se escriben en orden decreciente de grado se obtiene la siguiente secuencia:
A5, A3, A7, A1, A2, A4, A6, A8
El primer color se asigna a los vértices A5 y A1. El segundo color se asigna a los vértices A3, A4 y A8. El tercer color se asigna a los vértices A7, A2 y A6. A todos los vértices se ha asignado un color, de modo que G es 3-coloreable. Observe que G no es 2-coloreable puesto que a los vértices A1, A2 y A3, que están unidos entre sí, deben asignarse colores diferentes. En consecuencia, χ(G) = 3.
b) Considere el grafo completo Kn con n vértices. Puesto que cada vértice es adyacente a cualquier otro vértice, Kn requiere n colores en cualquier coloreado. Por tanto, χ(Kn) = n. No hay ninguna forma sencilla para determinar realmente si un grafo arbitrario es n-coloreable. Sin embargo, el siguiente teorema proporciona una caracterización simple de grafos 2-coloreables.
4.8.1 Teorema de los cuatro colores
Teorema de los cuatro colores (de Appel y Haken): Si las regiones de cualquier mapa M se colorean de modo que regiones adyacentes tengan colores distintos, entonces no se requieren más de cuatro colores.
Para demostrar el teorema anterior se usan computadoras; puesto que Appel y Haken demostraron por primera vez que si el teorema de los cuatro colores es falso, entonces debe haber un contraejemplo entre aproximadamente 2 000 tipos distintos de grafos planos. Entonces demostraron, usando una computadora, que ninguno de estos tipos de grafos posee tal contraejemplo. El análisis de cada tipo de grafo diferente parece estar más allá del alcance del ser humano sin el uso de una computadora. Por tanto la demostración, a diferencia de la mayor parte de las demostraciones en matemáticas, depende de la tecnología; es decir, depende del desarrollo de computadoras de alta velocidad.
5.1 Propiedad de los arboles
El árbol binario es una estructura fundamental en matemáticas y computación y también se le aplican algunos de los términos de los árboles con raíz como arista, camino, rama, hoja, profundidad y número de nivel. No obstante, en los árboles binarios se usará el término nodo, en lugar de vértice. Debe tener en cuenta que un árbol binario no es un caso especial de un árbol con raíz; son entes matemáticos diferentes.
Un árbol binario T es un conjunto finito de elementos que se denominan nodos, tales que:
1) T es vacío (árbol nulo o árbol vacío), o
2) T contiene un nodo distintivo R, denominado raíz de T, y los nodos restantes de T forman un par ordenado de árboles binarios ajenos T1 y T2. Si T contiene una raíz R, entonces los árboles T1 y T2 se denominan, respectivamente, subárbol izquierdo y subárbol derecho de R. Si T1 no es vacío, entonces su raíz se denomina sucesor izquierdo de R; en forma semejante, si T2 no es vacío, entonces su raíz se denomina sucesor derecho de R. La definición anterior de un árbol binario T es recursiva, ya que T se define en términos de los subárboles binarios T1 y T2. Esto significa, en particular, que cualquier nodo N de T contiene un subárbol izquierdo y un subárbol derecho, y que cada subárbol o ambos pueden ser vacíos. Así, cualquier nodo N en T tiene 0, 1 o 2 sucesores. Un nodo sin sucesores se denomina nodo terminal. Por tanto, los dos subárboles de un nodo terminal son vacíos.
Representación de un árbol binario
Un árbol binario T suele presentarse por medio de un diagrama en el plano, denominado ilustración de T. En específico, el diagrama de la siguiente figura representa un árbol binario ya que:
i) T consta de 11 nodos, que se representan con las letras A a L, excepto la I.
ii) La raíz de T es el nodo A en la parte superior del diagrama.
iii) Una línea inclinada hacia la izquierda en un nodo T indica un sucesor izquierdo de N; y una línea inclinada hacia la derecha en T indica un sucesor derecho de N.
Por consiguiente.
a) B es un sucesor izquierdo y C es un sucesor derecho de la raíz A.
b) El subárbol izquierdo de la raíz A consta de los nodos B, D, E y F, y el subárbol derecho consta de los nodos C, G, H, J, K y L.
c) Los nodos A, B, C y H tienen dos sucesores; los nodos E y J tienen sólo un sucesor, y los nodos D, F, G, L y K no tienen sucesores; es decir, son nodos terminales.
5.2 Arboles generadores
El árbol de un grafo es un subgrafo del grafo que es, en sí mismo, un árbol. En tanto, un árbol generador de un grafo conexo constituye un subgrafo generador que es un árbol.
Considérese el grafo G de la figura. En la misma figura, G' es un árbol del grafo G, ya que es un subgrafo de G, que es un árbol. Por último, en esta figura, G'' es un árbol generador del grafo G, ya que es un subgrafo generador de G, que es un árbol.
5.2.1 Búsqueda de anchura (BFS)
La idea general detrás de una búsqueda en anchura que empieza en un vértice inicial A es la siguiente: primero se procesa el vértice inicial A. Luego se procesan todos los vecinos de A. Enseguida se procesan todos los vecinos de los vecinos de A. Lo natural es seguir la pista de los vecinos de un vértice, y es necesario garantizar que ningún vértice sea procesado dos veces. Esto se logra mediante el uso de una QUEUE para mantener los vértices que están en espera de ser procesados, y por un campo STATUS que indica el estado actual de un vértice. El algoritmo sólo procesa los vértices que están unidos al vértice inicial A; es decir, el componente conexo incluyendo a A. Suponga que desea procesar todos los vértices en el grafo G. Entonces es necesario modificar el algoritmo de modo que empiece de nuevo con otro vértice (que se denomina B) que aún se encuentre en el estado ready (STATUS = 1). Este vértice B puede obtenerse recorriendo la lista de vértices.
Ejemplo.
Los vértices se procesan en el siguiente orden:
A, B, C, D, K, L, J, M
En la figura a) se muestra la secuencia de las listas de espera en QUEUE y la secuencia de los vértices que están siendo proce sados. (Observe que después de procesar el vértice A, sus vecinos B, C y D se añaden a QUEUE en el orden primero B, luego C y por último D; por tanto, B está al frente de la QUEUE y así B es el siguiente vértice que será procesado.) De nuevo, cada vértice, excluyendo a A, proviene de una lista de adyacencia y, por tanto, corresponde a una arista del grafo. Estas aristas forman un árbol de expansión de G que se muestra en la figura b). Una vez más, los números indican el orden en que las aristas se agregan al árbol de expansión. Observe que este árbol de expansión es diferente al de la figura b), que proviene de una búsqueda en profundidad.
(Búsqueda en anchura): Al empezar en un vértice inicial A, este algoritmo ejecuta una búsqueda
en anchura sobre un grafo G.
Paso 1. Todos los vértices se inicializan en el estado ready (STATUS = 1).
Paso 2. El vértice inicial A se coloca en QUEUE y el estado de A se cambia al estado waiting (STATUS = 2).
Paso 3. Se repiten los pasos 4 y 5 hasta que QUEUE esté vacía.
Paso 4. Se elimina el vértice frontal N en QUEUE. Se procesa N y se hace STATUS (N) = 3, el estado processed.
Paso 5. Se analiza cada vecino J de N.
a) Si STATUS (J) = 1 (estado ready), J se agrega a la parte trasera de QUEUE y se restablece STATUS
(J) = 2 (estado waiting).
b) Si STATUS (J) = 2 (estado waiting) o STATUS(J) = 3 (estado processed), se ignora el vértice J.
[Fin del ciclo del paso 3].
Paso 6. Salir.
5.2.2 Búsqueda de profundidad (DFS)
La idea general detrás de una búsqueda en profundidad que empieza en un vértice inicial A es la siguiente: primero se procesa el vértice inicial A. Luego se procesa cada vértice N a lo largo de un camino P que empieza en A; es decir, se procesa un vecino de A, luego un vecino de A y así sucesivamente. Después de llegar a un “punto muerto”; es decir, aun vértice sin vecino no procesado, se retrocede en el camino P hasta que es posible continuar a lo largo de otro camino P ́. Y así en lo sucesivo. El retroceso se logra usando una STACK para mantener los vértices iniciales de posibles caminos futuros. También se requiere un campo STATUS que indique el estado actual de cualquier vértice, de modo que ningún vértice sea procesado más de una vez. El algoritmo procesa sólo aquellos vértices que están unidos al vértice inicial A; es decir, el componente conexo que incluye a A. Suponga que se desea procesar todos los vértices del grado G. Entonces es necesario modificar el algoritmo de modo que empiece de nuevo con otro vértice (que se denomina B) que aún se encuentre en el estado ready (STATE = 1). Este vértice B se obtiene al recorrer la lista de vértices.
Ejemplo
Suponga que el algoritmo 8.5 de búsqueda en profundidad en la figura 8-31 se aplica al grafo en la figura 8-30.
Los vértices se procesan en el siguiente orden:
A, D, L, K, C, J, M, B
En la figura a) se muestra la secuencia de los vértices que están en proceso y la secuencia de las listas de espera en STACK. (Observe que después que se procesa el vértice A, sus vecinos B, C y D se añaden a STACK en el orden primero B, luego C y por último D; por tanto, D está en la parte superior de STACK y D es el siguiente vértice que será procesado.) Cada vértice, excluyendo a A, proviene de una lista de adyacencia y entonces corresponde a una arista del grafo. Estas aristas constituyen un árbol de expansión de G que se muestra en la figura b). Los números indican el orden en que las aristas se agregan al árbol de expansión, y las líneas discontinuas indican retroceso.
5.3 Arboles generadores minimalistas
Suponga que G es un grafo ponderado conexo. Es decir, a cada arista de G se asigna un número no negativo denominado peso de la arista. Entonces a cualquier árbol de expansión T de G se asigna un peso total que resulta de sumar los pesos de las aristas en T. Un árbol de expansión mínima de G es un árbol de expansión cuyo peso total es el más
pequeño posible. Los algoritmos 8.2 y 8.3, permiten encontrar un árbol de expansión mínima T de un grafo ponderado conexo G, donde G tiene n vértices. (En cuyo caso T debe tener n − 1 aristas.)
Algoritmo 8.2: La entrada es un grafo ponderado conexo G con n vértices.
Paso 1. Las aristas de G se disponen en orden decreciente de peso.
Paso 2. Se procede secuencialmente para eliminar cada arista que no haga inconexo al grafo, hasta que queden
n − 1 aristas.
Paso 3. Salir.
Algoritmo 8.3 (de Kruskal): La entrada es un grafo ponderado conexo G con n vértices.
Paso 1. Las aristas de G se disponen en orden creciente de peso.
Paso 2. Se empieza sólo con los vértices de G y en forma secuencial se agrega cada arista que no origine un ciclo
hasta que se hayan agregado n − 1 aristas.
Paso 3. Salir.
El peso de un árbol de expansión mínima es único, aunque el árbol de expansión mínima en sí no lo es. Cuando dos o más aristas tienen el mismo peso pueden ocurrir distintos árboles de expansión mínima. En este caso, la disposición de las aristas en el paso 1 de los algoritmos 8.2 u 8.3 no es única, y así resultan árboles de expansión mínima distintos, como se ilustra en el siguiente ejemplo.
Aquí se aplica el algoritmo 8.2.
Primero se ordenan las aristas en orden decreciente de peso y luego en forma consecutiva se eliminan las aristas sin hacer inconexo a Q hasta que queden cinco aristas. Así se obtienen los datos siguientes:
Así, el árbol de expansión mínima de Q que se obtiene contiene las aristas BE, CE, AE, DF, BD
El peso del árbol de expansión es 24 y se muestra en la figura B)
Aquí se aplica el algoritmo 8.3.
Primero se ordenan las aristas en orden creciente de peso y enseguida se agregan las aristas sin formar ningún ciclo hasta que se incluyen cinco aristas. Así se obtienen los datos siguientes:
Así, el árbol de expansión mínima de Q contiene las aristas BD, AE, DF, CE, AF.
El árbol de expansión se muestra en la figura C). Observe que este árbol de expansión no es el mismo que se obtuvo al usarel algoritmo 8.2 y que, como era de esperar, su peso también es 24.
5.4 Recorrido de un árbol
Para acceder a los datos almacenados en un árbol, primero es necesario recorrer el árbol o visitar los nodos de este. Para lograr el recorrido de un árbol existen diferentes métodos, pues en la mayoría de las aplicaciones resulta muy importante el orden en que son visitados los nodos.
Se dice que se logra un recorrido de un árbol binario siempre que cada nodo del árbol sea visitado una y solo una vez. Básicamente hay dos formas principales de llevar a cabo el recorrido de un árbol, las cuales se describen a continuación:
1.Recorrido en profundidad. En este tipo de recorrido se sigue un camino, comenzando desde la raíz, a través de un hijo, siguiendo al descendiente más cercano del primer hijo antes de continuar con el segundo hijo. En resumen, en el recorrido de profundidad se recorren todos los descendientes del primer hijo, después se recorren todos los descendientes del segundo hijo, y así sucesivamente.
2. Recorrido en anchura. En este tipo de recorrido se sigue un camino “horizontal”, que empieza en la raíz, a través de todos sus hijos, luego se recorren los hijos de sus hijos y así sucesivamente, hasta que se recorren todos los nodos. En resumen, en el recorrido de anchura se recorre por completo cada nivel, antes de comenzar con el siguiente nivel.
Recorrido en preorden
El recorrido en preorden (nodoizquierdoderecho o NID) se resume en tres pasos principales:
1. Visitar el nodo raíz (N)
2. Recorrer el árbol izquierdo (I) en preorden (NID)
3. Recorrer el subárbol derecho (D) en preorden (NID)
Por tanto, en el recorrido en preorden, en primer lugar se visita la raíz del árbol y luego el subárbol izquierdo (que es a su vez un árbol), utilizando el orden nodoizquierdoderecho. Una vez recorrido el subárbol izquierdo se continúa con el derecho utilizando el orden NID.
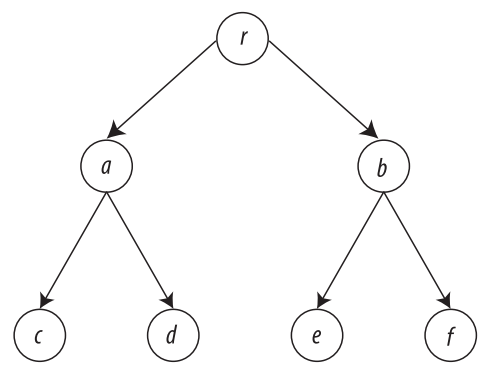
Ejemplo
Considérese el árbol de la figura. En este caso, para este árbol se realiza el recorrido en preorden de acuerdo con los dos pasos siguientes:
1. Se visita la raíz (nodo r).
2. Se recorre el subárbol izquierdo de r, el cual se compone de los nodos a, c y d. Considerando que el subárbol es, a su vez, un árbol, primero se recorre el nodo a, después el c (izquierdo) y por último el d (derecho).
3. Se continúa con el recorrido del subárbol derecho de r, que es un arbol con nodos b, e y f. Otra vez se sigue el orden NID, recorriendo en primer lugar el nodo b, luego el nodo e (I) y al final el nodo f (D). Por tanto, el recorrido en preorden para el árbol de la figura es:
r-a-c-d-b-e-f
Recorrido en enorden
El recorrido en enorden (izquierdonododerecho o IND) puede resumirse en tres pasos principales:
1. Recorrer el subárbol izquierdo (I) en enorden (IND)
2. Visitar el nodo raíz (N)
3. Recorrer el subárbol derecho (D) en enorden
Entonces, de acuerdo con lo expuesto antes, en este tipo de recorrido de un árbol binario, primero se recorre el subárbol izquierdo, después la raíz y por último el subárbol derecho.
Ejemplo
Considérese el árbol de la figura. En este caso, para este árbol se realiza el recorrido enorden de acuerdo con los pasos siguientes:
1. se visita el subárbol izquierdo del nodo raíz, el cual contiene los nodos a, c y d, y es, en sí mismo, otro árbol con raíz a; para recorrerlo se sigue el orden IND, es decir, se recorre en primer lugar el nodo c (nodo izquierdo), a continuación el nodo a (raíz) y finalmente el nodo d (nodo derecho); 2. una vez recorrido el subárbol izquierdo, se visita la raíz r.
3. por último se visita el subárbol derecho, que consta de los nodos b, d y e. Siguiendo el orden IND en el subárbol derecho, se visita primero el nodo e (nodo izquierdo), luego el nodo b (raíz) y finalmente el nodo e (nodo derecho). Por tanto, el recorrido en enorden para el árbol de la figura es:
c-a-d-r-e-b-f.
Recorrido en postorden
El recorrido en postorden (izquierdoderechonodo o IDN) se resume en tres pasos principales:
1. Recorrer el subárbol izquierdo (I) en postorden (IDN)
2. Recorrer el subárbol derecho (D) en postorden (IDN)
3. Visitar el nodo raíz (N)
Entonces, en este tipo de recorrido de un árbol binario, primero se recorre el subárbol izquierdo, después el subárbol derecho y por último el nodo raíz.
Ejemplo
Considérese el árbol de la figura. En este caso, se realiza el recorrido postorden de acuerdo con los siguientes pasos:
1. se visita el subárbol izquierdo del nodo raíz, el cual contiene los nodos a, c y d, y es, en sí mismo, otro árbol con raíz a; para recorrerlo se sigue el orden IDN, es decir, se recorre en primer lugar el nodo c (nodo iz quierdo), a continuación el nodo d (nodo derecho) y al final el nodo a (nodo raíz).
2. una vez recorrido el subárbol izquierdo se recorre el subárbol derecho de r, que consta de los nodos b, d y e; siguiendo el orden IDN en el subárbol derecho, se visita primero el nodo e (nodo izquierdo), luego el nodo f (nodo derecho) y enseguida el nodo b (nodo raíz).
3. Por ultimo, se visita el nodo raíz r. Por tanto, el recorrido en postorden para el árbol de la figura es:
c-d-a-e-f-b-r
Referencias
Becerra, J. F. V., & Sandoval, A. G. (2014). Matemáticas Discretas: Aplicaciones y Ejercicios. Azcapotzalco, Mexico: Grupo Editorial Patria.
Lipschutz, S. & Lars, M (2009). Matematicas Discretas. Álvaro Obregón, Mexico. Grupo editorial McGRAW-HILL/INTERAMERICANA
Grassmann. (1996). Mathematica Discreta Y Logica. London, England: Prentice Hall & IBD.
Epp, S. (2011). Matematicas Discretas con Aplicaciones (4th ed.). Mexico City, Mexico: Cengage Learning Editores S.A. de C.V.





























Comentarios
Publicar un comentario